Reimagining the Data Stack for AI's Realities
Modern data stacks face challenges with AI workloads, requiring a re-evaluation of architecture, governance, and real-time processing. A new approach is needed to bridge the gap between idealized data flows and practical implementations.
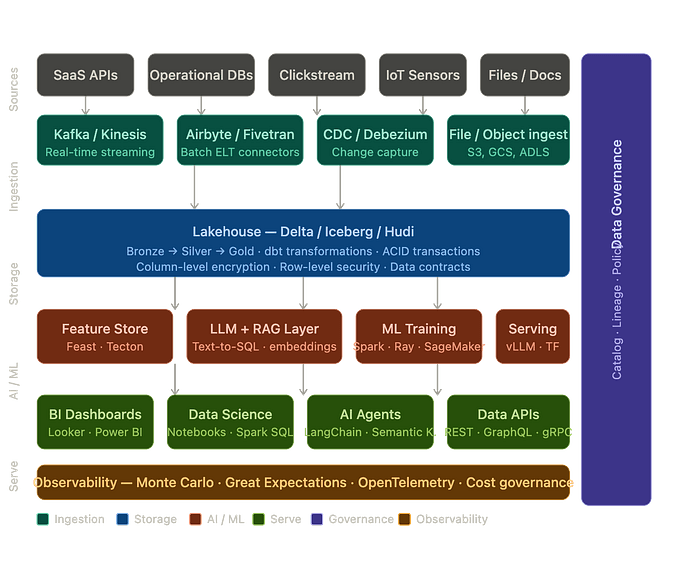
The traditional data stack may no longer cut it in the age of AI. While conference slides often depict elegant data pipelines, the reality inside companies is far messier. Teams grapple with Kafka topics bearing various schemas and dbt models that drift silently off course. AI features often end up as simple API calls lacking strong error handling.
Old Stacks Crumble Under AI Pressure
Consider the conventional warehouse-centric stack, exemplified by Redshift or BigQuery. It's designed for structured data inputs and SQL query outputs. However, AI disrupts this model. New requirements like raw text processing, real-time embedding computations, and precise data lineage tracking don't fit neatly.
That's where the Lakehouse architecture steps in. Featuring platforms like Delta Lake and Apache Iceberg, it's an attempt to blend the flexibility of data lakes with reliable transactional integrity. Yet, even this setup isn't enough without further refinement.
The Platinum Layer: A Missing Piece?
Enter the Medallion Architecture, familiar with its Bronze, Silver, and Gold tiers. However, the 'Platinum' or AI-native layer is often overlooked. To make data truly AI-ready, beyond cleaning, involves computing embeddings, curating fine-tuning datasets, and pre-materializing feature vectors. Teams that treat this as optional may struggle when retrofitting becomes necessary.
Why isn't this usually planned from the outset? Perhaps it's the perceived complexity or delayed ROI. But without it, auditing becomes a nightmare, and AI capabilities remain stunted.
Rethinking Real-Time and Batch Processing
The debate between Lambda and Kappa architectures has largely settled. The key takeaway is integration. Iceberg can serve as a unification point, allowing both real-time and batch processes to coexist. With micro-batches from Flink and partitioning from Spark, consistency is maintained.
However, each path demands distinct monitoring and alerting. One size doesn't fit all, and attempts to unify these into a single process often end with inefficiency and frustration. The separation of latency SLOs into seconds for real-time and hours for batch is critical.
Governance: The Unsung Foundation
Data governance often gets short shrift, designed last and regretted first. Skimping on governance can lead to significant repercussions, like inadvertent PII leaks or handicapped auditing capabilities. Column-level lineage and data contracts are non-negotiable when dealing with AI.
Why trust in governance? It's simple: without it, the integrity of your data pipeline and the reliability of your AI models are in jeopardy. OpenLineage and tools like Soda Core can help enforce necessary standards, ensuring data contracts are honored and breaches are caught early.
In a world where AI demands more from your data infrastructure, clinging to outdated paradigms is a recipe for inefficiency. Companies must evolve their data stacks, embracing architectures that support AI's unique requirements. The market map tells the story, and those who adapt will lead the charge.
Get AI news in your inbox
Daily digest of what matters in AI.
Key Terms Explained
A dense numerical representation of data (words, images, etc.
The process of measuring how well an AI model performs on its intended task.
The process of taking a pre-trained model and continuing to train it on a smaller, specific dataset to adapt it for a particular task or domain.