Google's Gemma 4: Breaking the AI Mold on Consumer GPUs
Google's Gemma 4 model showcases a breakthrough in AI compression, fitting 26 billion parameters into just 15GB and operating on a single GPU with minimal performance loss.
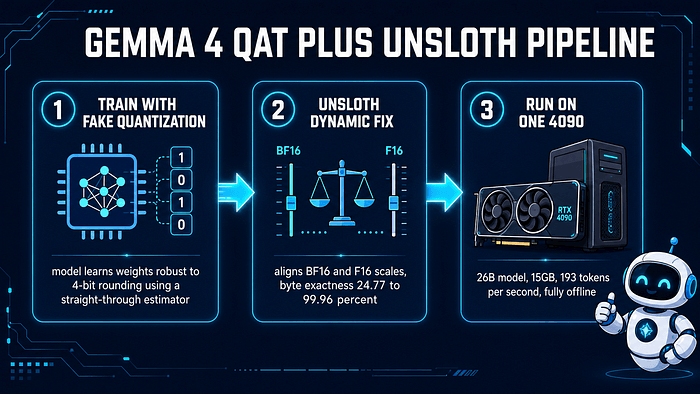
Google has pulled off something remarkable with its new Gemma 4 model. The tech giant has managed to shrink this massive 26-billion-parameter AI model into just 15GB of memory. That's a feat that allows Gemma 4 to run at 193 tokens per second on a single consumer GPU. We're talking about hardware that most folks use for gaming, not datacenters.
The Magic Behind Gemma 4
How did Google achieve this? The company employed quantization-aware training (QAT) and a clever conversion trick courtesy of Unsloth, which helped address a pesky 4-bit bug. This isn't just about squeezing big models into small spaces. The real story is that Gemma 4's performance remains nearly intact despite the radical compression. It's a move that defies conventional wisdom around quantization, where reducing precision typically means sacrificing smarts.
Why This Matters
For AI developers, this is a potential major shift. The capex needed for powerful infrastructure could drop significantly, democratizing advanced AI capabilities. Gemma 4 isn't just a technical marvel. It's a sign that the quality-vs-speed tradeoff is rapidly narrowing. If a model this large can run effectively on consumer-grade hardware, what does that say about the future of AI accessibility?
Beyond the Hype
But let's not get carried away. While 4-bit models like Gemma 4 are impressive, they're still 4-bit. There's a limit to how much precision loss can be tolerated before it affects outcomes. Yet, the strategic bet is clearer than the street thinks. Google is signaling that the barriers to high-performance AI are lowering. What happens when real-time AI becomes ubiquitous across devices, not just in elite research labs?
The earnings call told a different story. Google's focus on compression and efficiency is a long-term play, betting on broader enterprise adoption. The street might miss this nuance, but it's a turning point shift.
The Practical Side
For those ready to dive into using Gemma 4, there are various deployment paths: from API servers to browser-based ONNX implementations. The flexibility is there, but the decision on which model to choose boils down to available hardware and specific needs. In this space, reading the 10-K, not the press release, is important for understanding the full scope of what's happening.
So, is Gemma 4 the future of AI on your desktop? With advancements like this, it's hard to bet against it.
Get AI news in your inbox
Daily digest of what matters in AI.
Key Terms Explained
Graphics Processing Unit.
A value the model learns during training — specifically, the weights and biases in neural network layers.
Reducing the precision of a model's numerical values — for example, from 32-bit to 4-bit numbers.
The process of teaching an AI model by exposing it to data and adjusting its parameters to minimize errors.