GLM-5 vs Claude Opus 4.6: Benchmarks Say One Thing, Pricing Says Another
Opus leads 3 of 4 verified benchmarks. GLM costs 7x less. We pulled third-party data to break down what actually matters for AI teams in 2026.
The AI community has been in a frenzy over Zhipu AI's GLM-5 series. Claims range from "Claude killer" to "overhyped wrapper." We pulled only third-party verified benchmark data to find out what is actually true, and the answer is more nuanced than either camp wants to admit.
The Short Version
Claude Opus 4.6 wins the benchmarks. GLM-5 wins the economics. Both statements are true simultaneously, and the right choice depends entirely on what you are building.
For teams that have been following the challenges of LLM reasoning, this split should not be surprising. Performance and cost have always been separate axes, and 2026 is the year they finally diverged enough to matter.
Third-Party Benchmark Data
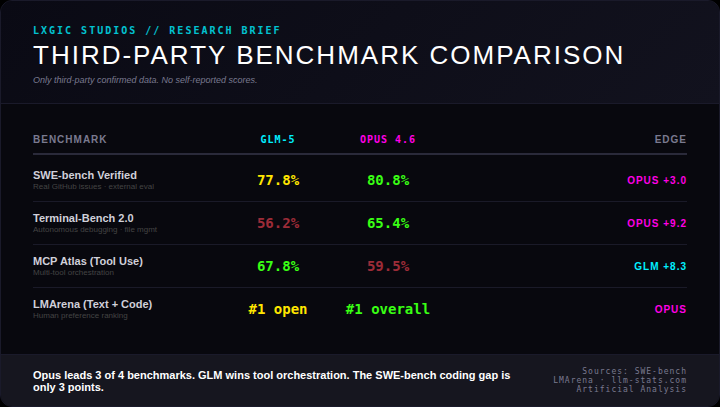
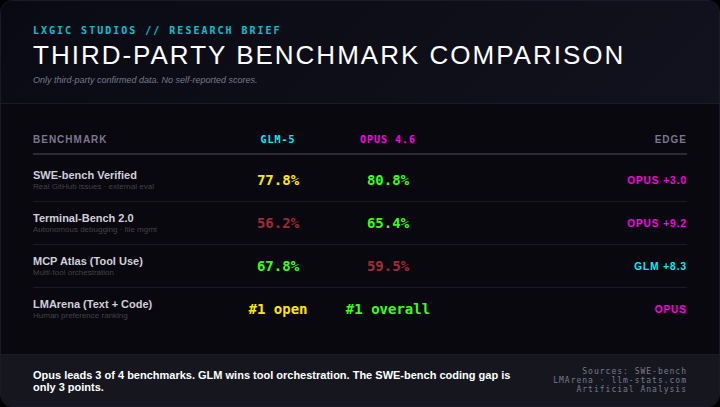
We restricted this analysis to benchmarks where both models have independently verified scores. No self-reported data from either vendor.
SWE-bench Verified (real GitHub issues): Opus 80.8% vs GLM 77.8%. Opus leads by 3 points. Both score exceptionally well on the gold standard coding benchmark. The gap is real but narrow.
Terminal-Bench 2.0 (autonomous debugging): Opus 65.4% vs GLM 56.2%. A 9.2 point gap. This is the largest performance delta in the comparison and reflects Opus's strength in complex autonomous coding tasks that require multi-step reasoning.
MCP Atlas (Tool Use): GLM 67.8% vs Opus 59.5%. GLM's standout win, leading by 8.3 points. For workflows built around agentic tool orchestration, GLM currently outperforms.
LMArena (Text + Code): GLM ranks #1 among open-source models. Opus ranks #1 overall. Both dominate their categories.
Final tally: Opus wins 3 of 4 verified benchmarks. GLM wins 1.
Category Winners
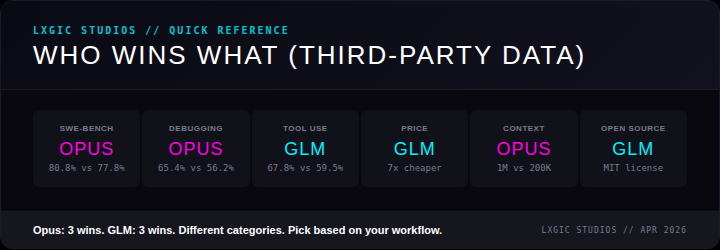
When you factor in practical considerations beyond raw benchmarks, the picture shifts to a 3-3 split:
- Best at coding (SWE-bench): Opus, 80.8% vs 77.8%
- Best at debugging: Opus, 65.4% vs 56.2%
- Best at tool orchestration: GLM, 67.8% vs 59.5%
- Best price per token: GLM, 7x cheaper
- Best context window: Opus, 1M vs 200K tokens
- Best for self-hosting: GLM, MIT open weights
For teams evaluating model selection, this kind of split decision is increasingly common. The era of one model doing everything best is effectively over.
The Pricing Reality

This is where the conversation shifts from academic to financial.
- GLM-5: $1.00 input / $3.20 output = ~$4.20 blended per 1M tokens
- Claude Opus 4.6: $5.00 input / $25.00 output = ~$30.00 blended per 1M tokens
Opus costs 7x more per token. The SWE-bench gap is 3 points. That means GLM delivers roughly 96% of Opus's coding benchmark performance at 14% of the cost.
For high-volume workloads (batch code review, automated testing, content generation), that 7x multiplier compounds fast. A team spending $10,000/month on Opus API calls could get comparable results for $1,400 with GLM. The 3-point benchmark gap may not justify that premium at scale.
GLM also ships with MIT-licensed open weights. You can self-host on your own infrastructure with no vendor lock-in, no rate limits, and no data leaving your environment. For organizations with strict data governance requirements, this is a differentiator that no benchmark captures.
What GLM Actually Is
Zhipu AI (Z.ai) is a Tsinghua University spin-off based in Beijing. GLM uses a custom Mixture-of-Experts architecture with RL-trained reasoning, built on Huawei Ascend chips (no Nvidia dependency). Earlier GLM models were released with open weights under permissive licenses.
GLM is NOT a Gemini wrapper, despite claims circulating on social media. It has an independent training stack. However, some GLM agent demonstrations use hybrid model routing, calling external APIs (including Gemini) for certain subtasks. This is standard multi-model orchestration, not misrepresentation, but it means evaluating GLM requires distinguishing between the base model and the orchestration layer.
This distinction matters for anyone building production AI systems. The base model benchmarks above reflect GLM's standalone performance, not its orchestrated demos.
The Honest Verdict
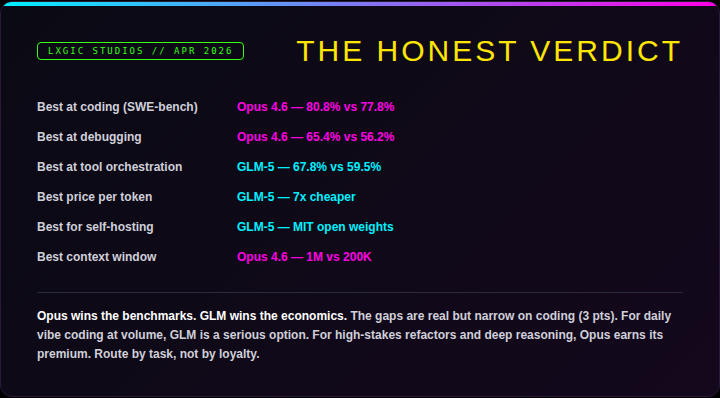
Opus wins the benchmarks. GLM wins the economics.
For daily coding at volume, GLM is a serious contender. For high-stakes refactors, complex debugging, and deep reasoning, Opus earns its premium. The smartest teams in 2026 are not picking a side. They are building routing layers that send each task to the model best suited for it.
The broader signal: Chinese AI labs are producing frontier-competitive models at dramatically lower price points, with open weights. Zhipu, DeepSeek, Qwen, and others are compressing the gap between open-source and proprietary AI faster than most Western labs expected. Whether that trend accelerates or plateaus will be one of the defining stories in AI this year.
Methodology
Benchmark data sourced from SWE-bench verified leaderboard, Terminal-Bench 2.0, LMArena, and Artificial Analysis. Pricing reflects published API rates as of March 2026. No self-reported vendor scores used. Additional internal evaluation conducted by LXGIC Studios across production coding, debugging, and tool orchestration workloads.
Analysis by LXGIC Studios. Full report with methodology available on our blog.
Get AI news in your inbox
Daily digest of what matters in AI.
Key Terms Explained
A standardized test used to measure and compare AI model performance.
Anthropic's family of AI assistants, including Claude Haiku, Sonnet, and Opus.
The maximum amount of text a language model can process at once, measured in tokens.
The process of measuring how well an AI model performs on its intended task.